Azure在2018年推出了Data Explorer产品,提供实时海量流数据的分析服务(非流计算),面向应用、网站、移动端等设备。
该服务面向秒-分钟级拿到结果的场景,类OLAP,对TP场景不敏感。
产品起源
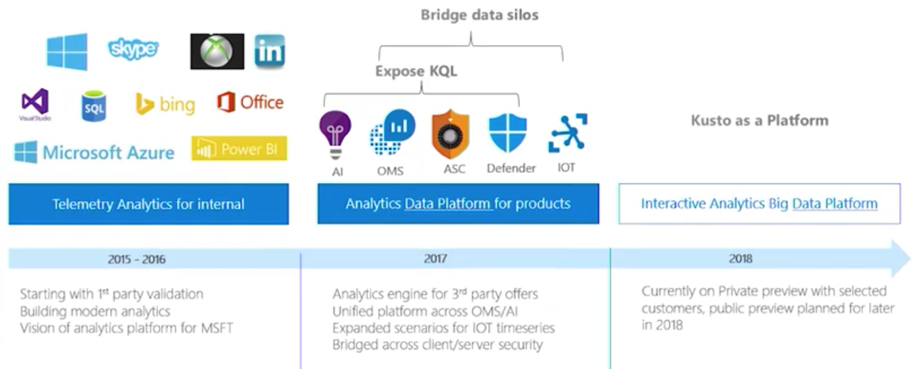
Azure Data Explorer(ADE)内部代号叫Kusto,在Kusto之前,Azure对监控和分析场景散落在各产品中,例如:Log Analytics、Application Insight,Azure Monitor,Time Series Insight,这些产品在用不同的技术架构来解决不同数据源等问题,例如:
-
通过PerfCounter和Event通过流数据进行聚合告警
-
利用通用计数器写入时序数据库,配置实时Dashboard
-
把应用数据写到数仓做深入分析
ADE的目标是对上层预定义计算、后计算做一层抽象:将原始数据进行通用存储,保留一段时间(例如几个月),对这些多样化数据进行快速的多维分析。
ADE在微软的内部代号为Kusto,由以色列研发团队提供。Azure Log Analytics开始选型是Elastic Search,每年付1M$用来获得支持,但效果不好,因此在2015年时对日志、Metric场景使用Kusto来提供,包括之前在cosmosDB中的分析工作。
截止 September 2018 的数据:
-
hundreds of teams within Microsoft
-
41 Azure regions as 2800 Engine+DM cluster pairs
-
about 23000 VMs.
-
overall data size stored in Kusto and available for query is 210 petabytes
-
6 petabytes ingested daily.
-
around 10 billion queries per month.
可以推测平均存储时间为:210 (PB) / 6 (PB) = 35 天
产品定义
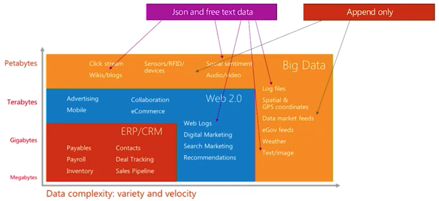
面向数据类型是Immutable Data,特点是AppendOnly,并且大部分都是Semi-Structure Data,例如User Click Log,Access Log等。Big Data理论中90%都是这类数据,这也是Big Data理论数字化并洞察物理时间的基础。
从Facebook等数据来看,2017年时每天用户产生的视频(UGC)大约在10PB,但用户点击产生的日志量已经远远超过10PB这量,对视频网站而言,内容数据增量少于点击日志的增量已成为通用的规律。
Azure在宣传时这样定义自己的产品:
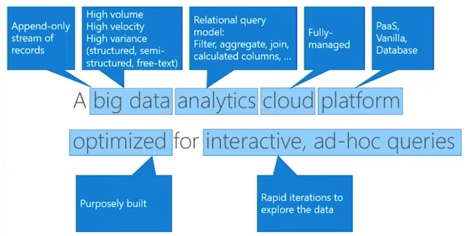
fast, fully managed data analytics service for real-time analysis on large volumes of data streaming from applications, websites, IoT devices, and more.
产品主要解决三类问题:
-
Customer Query (Advance Hunting)
-
Interactive UI (前者封装)
-
Background Automation(定时任务)
也有一些解释基于几个交互式产品来解释:底层是实时OLAP,上层是Jupiter(交互式) + Kibana(可视化)
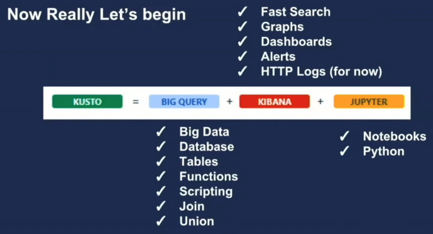
从产品定位角度考虑,ADE处于中间层次(利用人的交互式分析能力进行发掘与探索):
-
integrates with other major services to provide an end-to-end solution
-
pivotal role in the data warehousing flow by executing the EXPLORE step of the flow on terabytes of diverse raw data
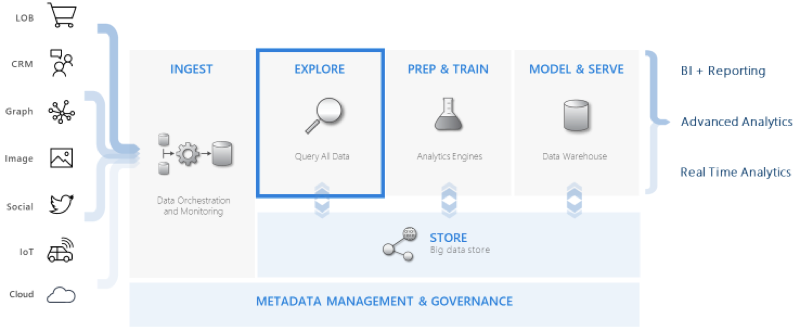
除此之外ADE(Kusto)是
-
azure application insight, log analytics 基础
-
为Azure Monitor, Azure Time Series Insights, and Windows Defender Advanced Threat Protection提供数据服务
-
提供REST API, MS-TDS, and Azure Resource Manager service endpoints and several client libraries
数据模型与API
ADE以实例方式给用户付费,用户购买一组实例后可以创建:
-
Database
-
Table:存储实例,包含Schema(表结构和字段类型),Mapping(如何从CSV、Avro等格式映射)
-
Functions:自定义函数,利用scalar语言可以定义自定义方法,方便后期处理
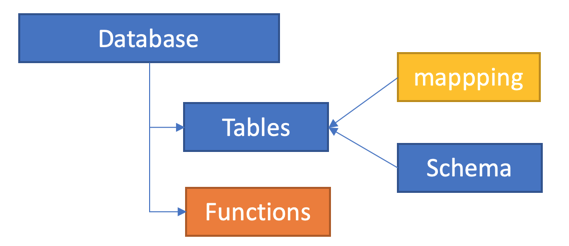
整个API只有一组接口,通过类KQL方法来管理控制流与数据流,控制流以”.”作为开头,例如 “.create table”。数据分析语言除了KQL外还支持SQL:
-
TSQL:https://docs.microsoft.com/en-us/azure/kusto/api/tds/t-sql
-
KQL:https://docs.microsoft.com/en-us/azure/kusto/query/index
以下是一些案例:
创建: .create table MyLogs ( Level:string, Timestamp:datetime, UserId:string, TraceId:string, Message:string, ProcessId:int32 ) 创建或追加: .create-merge tables MyLogs (Level:string, Timestamp:datetime, UserId:string, TraceId:string, Message:string, ProcessId:int32), MyUsers (UserId:string, Name:string) .alter column ['Table'].['ColumnX'] type=string 更改列行为后,之前数据会变成Null,建议把数据筛选出来写入新的Table 映射关系: .create table MyTable ingestion csv mapping "Mapping1" '[{ "Name" : "rownumber", "DataType":"int", "Ordinal" : 0},{ "Name" : "rowguid", "DataType":"string", "Ordinal" : 1 }]’ .create table MyTable ingestion json mapping "Mapping1" '[{ "column" : "rownumber", "datatype" : "int", "path" : "$.rownumber"},{ "column" : "rowguid", "path" : "$.rowguid" }]' .ingest into table T ('adl://contoso.azuredatalakestore.net/Path/To/File/file1.ext;impersonate') with (format='csv’) .set RecentErrors <| LogsTable | where Level == "Error" and Timestamp > now() - time(1h) .ingest inline into table Purchases <| Shoes,1000 Wide Shoes,50 "Coats, black",20 "Coats with ""quotes""",5 .export async compressed to csv ( h@"https://storage1.blob.core.windows.net/containerName;secretKey", h@"https://storage1.blob.core.windows.net/containerName2;secretKey" ) with ( sizeLimit=100000, namePrefix=export, includeHeaders=all, encoding =UTF8NoBOM ) <| myLogs | where id == "moshe" | limit 10000 .export async to sql MySqlTable h@"Server=tcp:myserver.database.windows.net,1433;Database=MyDatabase;Authentication=Active Directory Integrated;Connection Timeout=30;" <| print Id="d3b68d12-cbd3-428b-807f-2c740f561989", Name="YSO4", DateOfBirth=datetime(2017-10-15) .set table Employees policy ingestiontime true Employees | where cursor_after('') Employees | where cursor_after('636040929866477946') // -> 636040929866477950 Employees | where cursor_after('636040929866477950') // -> 636040929866479999 Employees | where cursor_after('636040929866479999') // -> 636040939866479000 Tagging(用来管理Extent) .ingest ... with @'{"tags":"[\"drop-by:2016-02-17\"]"}' .drop extents <| .show table MyTable extents where tags has "drop-by:2016-02-17"
